Robots Used
Bunker

Spot


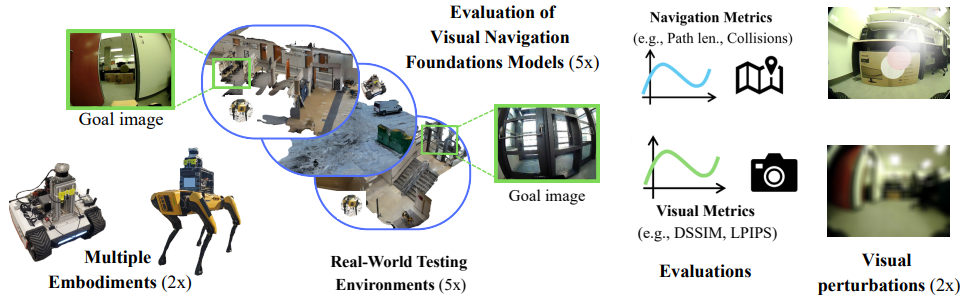
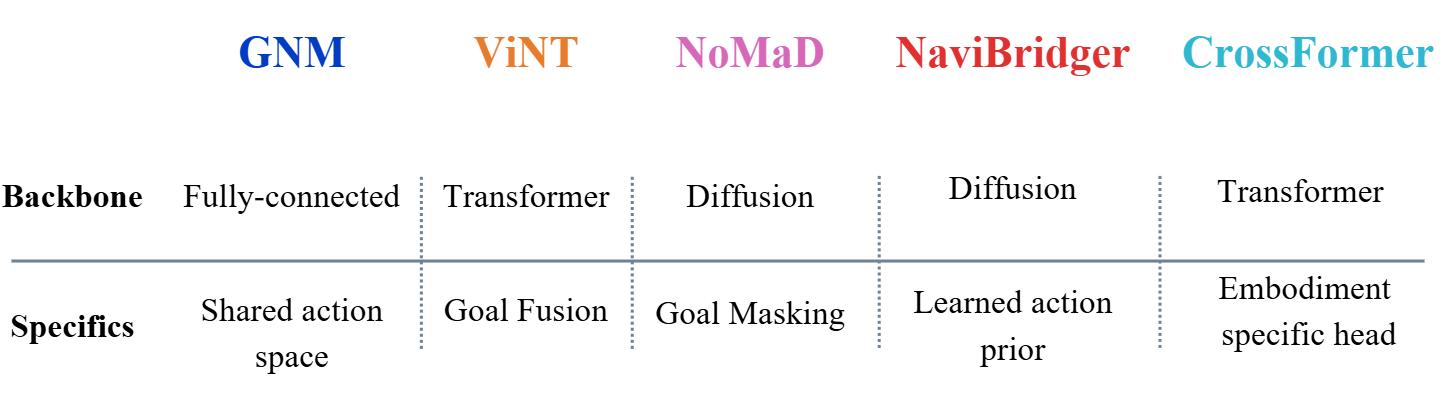
Visual Navigation Models (VNMs) promise generalizable, robot navigation by learning from large-scale visual demonstrations. Despite growing real-world deployment, existing evaluations rely almost exclusively on success rate, whether the robot reaches its goal, which conceals trajectory quality, collision behavior, and robustness to environmental change. We present a real-world evaluation of five state-of-the-art VNMs (GNM, ViNT, NoMaD, NaviBridger, and CrossFormer) across two robot platforms and five environments spanning indoor and outdoor settings. Beyond success rate, we combine path-based metrics with vision-based goal-recognition scores and assess robustness through controlled image perturbations (motion blur, sunflare). Our analysis uncovers three systematic limitations: (a) even architecturally sophisticated diffusion and transformer-based models exhibit frequent collisions, indicating limited geometric understanding; (b) models fail to discriminate between different locations that are perceptually similar, however some semantics differences are present, causing goal prediction errors in repetitive environments; and (c) performance degrades under distribution shift. We will publicly release our evaluation codebase and dataset to facilitate reproducible benchmarking of VNMs






@misc{guerrier2026visionfoundationmodelsnavigate,
title = {Can Vision Foundation Models Navigate? Zero-Shot Real-World Evaluation and Lessons Learned},
author = {Maeva Guerrier and Karthik Soma and Jana Pavlasek and Giovanni Beltrame}
year = {2026},
eprint = {2603.25937},
archivePrefix = {arXiv},
primaryClass = {cs.RO},
url = {https://arxiv.org/abs/2603.25937},
}